Webinar Recording and Transcript – March 2024
15 March 2024 – Extension and Q&A
With Sonya Chowdhury, Chris Ponting and Andy Devereux-Cooke
This webinar covers an update on DecodeME’s Extension, a project update, next steps for us and a Q&A session.
Watch the recording:
Direct link: Watch the recording on YouTube
Listen to the audio:
Read the transcript:
SONYA
Hello and welcome everybody to another DecodeME webinar. I’m joined today by colleagues Chris Ponting and Andy Devereux-Cooke and they’ll be speaking in a moment want to welcome those people who are watching on the webinar, and those who have joined us through Facebook.

Slide 2, 1:28
Today we want to talk to you about our plans and next steps, and we will have an opportunity for questions. We are going to talk to you about the DecodeME study extension. We know that this may be a disappointment and frustration, we feel the same, so we want to share with you a little bit more information about that. Firstly, I can honestly say, hand on heart, the whole team has been working incredibly hard in the background; that includes our PPI, patient public involvement members, people with lived experience, the team in Edinburgh, the team at Action for M.E., and others that we’re working with.

Slide 3, 2:11
So, as many of you will know, we were originally due to complete the DecodeME study by August, this year. Throughout the project, and we’ve talked to you previously about some of them, we have faced challenges which have affected the timeline. Things like Amazon buying up all the boxes during the pandemic and lockdown impacted on us. We’ve had postal strikes and we’ve had changes in the people that have been working with us in we call the ‘supply chain’.
However, we’ve managed to overcome these. But, the one challenge that we were not able to overcome was the operational and capacity issues at UK Biocentre, and they’ve been the most significant factor affecting our project completion timeline.
While we have been able to mitigate some of the delays and worked incredibly hard with UK Biocentre, with meetings every week, sometimes every single day, to try and overcome the issues, we have not yet got all the data that we expected to have back from them at this point. When participants sent their samples in, they went to UK Biocentre, to be processed after which the data is send back to Edinburgh University. However, we have not yet got all of that data back.
I want to reassure you that nothing is going to happen with the samples that have been sent in. We will get the data. It’s just taking longer than we had expected.
And as a result, we now need more time in order to quality check and analyse the genetic data.
The people that have taken part in the study, completed questionnaires and sent in samples, have done an amazing job, but the next step, the extraction of that DNA from the saliva samples, at UK Biocentre, is what has really caused delays.
In short, we didn’t have enough time to perform all of the analysis required by August 2024, so we approached are funders and they have agreed to give us an extension. They have funded us for another year to enable us to do the work that we need to.
We discussed this situation with our Scientific Advisory Board, as well as our funders, and they also agreed with our assessment that the extension should give us sufficient time to finish the project.
I can honestly say, and you’ll hear this from Chris and also from Andy, people are working really hard and are committed to completing this research to the highest possible scientific standards, ensuring that our findings are as robust as possible.
We all know in the community that there have been many false starts and we are dedicated and committed to making sure that our findings are scientifically valid.
Our funders have given us extra money so that we keep the team in place, and it’s quite a large team, and they’re having to work really hard with quite a lot to do, but we will ensure that we deliver as soon as we can and give results as soon as we can, but we will only do that when they reach the standard required.
We are now working to a deadline of August 2025 and as I said we will release the results as soon as possible before this date.
I’m now going to hand over to Chris, who is going to tell you a little bit more about the work that we’re actually doing at the moment.
CHRIS
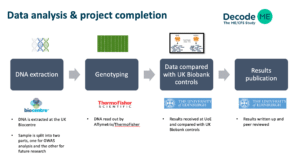
Slide 4, 5:40
Thank you Sonya.
Participants who provided DNA will remember that you sent your samples to UK Biocentre, and that is, for us, the beginning. There are so many steps after that but for you, you probably don’t know so much about what happens afterwards. So, I just thought I would go through each of the steps in turn to help you understand the complexity of the operation and what has caused the delays.
Firstly, when the samples arrive at UK Biocentre, the sample is split into two, and the second sample is kept for future research. The important thing is to say that each sample is incredibly valuable to us and we’ve managed to communicate to UK Biocentre, how valuable each sample is by going to visit them with members of the PPI team.
When UK Biocentre takes receipts of each sample, it associates a barcode with the sample, which allows the tracking of the sample going right from that point until the end when we do the analysis.
The amount of DNA in each sample then needs to be measured and after that the extraction occurs, and there is the ‘replating’ – this is means taking a portion of that sample and putting it onto a plate that, with other samples, which then goes to ThermoFisher, for genotyping. This is the second step.
Our plans have been very extensive. We have been planning for many years, but we didn’t plan for this. So, what’s been going wrong is that, at times, the samples have not been receipted properly when they turned up at the door of UK Biocentre. At times the tracking, with the barcode, wasn’t done to the highest standards and not all of the quantification of the DNA was done perfectly. So, there have unfortunately been errors and inconsistencies in the process that have caused us to meet with UK Biocentre twice a week to go through, literally sample by sample, what has happened for each one of them.
UK Biocentre have engaged in that process very well indeed. We have to thank them for that. They have produced a 62-page report about all of the different samples and what are the issues. We have gone through all of the checks, that they have now employed, and we’re signing that off soon. The first version of that report goes back to last summer. So, you can tell that we’ve been…. Well, I hope you can tell, we’ve been working hard on that every week, for those two meetings and holding to account the organisation that has been doing the work. This has not been something that we have been able mitigate.
The funders, when they gave us the extra money, said that their panel agreed that the major delays had been outside of the control of the principal investigator, ourselves, and were being actively managed by ourselves.
So, the first set of plates with the DNA samples have gone to ThermoFisher and have come back. The data coming back to us is the third step in the process, where we compare the data with UK Biobank controls and we’ve done that now for the first batch.
Last week we got back the second set of data, the second batch, and we’re looking through that now, making sure that it’s of high-quality and it does look like it’s of high quality.
There’ll be two more of those batches, which will come really quickly, because I’m pleased to tell you that there is no backlog of DNA extractions. Extractions are almost complete, but of course we’re still meeting twice a week to ensure that happens.
So, by the summer, we’ll have all of the data and will do the data cleaning, what’s called ‘quality control’, and then we’ll be comparing it with the DNA that comes from UK Biobank, which represents healthy controls.
This comparison should allow us to say where in the genome there are letter changes that are more frequent among people with ME than those in the general population. This indicates where in the genome there are risk factors for ME, which hopefully will tell us what are the systems that are going wrong in people with ME. If it’s the nervous system, the immune system, mitochondria, autonomic system etc.
That will allow us to put together all of the results and we will write them up as soon as we can for peer review, knowing that we have done the best possible job and we’ve done all the checks and balances.
![Replication of findings. Collaboration with Hanna Ollila & Anniina Tervi (Institute for Molecular Medicine, Finland [FIMM]) - FinnGenThey will share with us a meta-analysis of data from FinnGen, the MGB (Mass General Brigham Biobank - Richa Saxena and Jacqueline Lane), and the Estonian Biobank (Erik Abner).](https://www.decodeme.org.uk/app/uploads/2024/03/Screenshot-2024-03-20-at-17.10.19-300x169.png)
Slide 5, 12:14
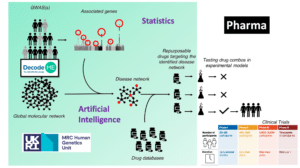
Slide 6, 13:22
It isn’t an academic exercise. What we are doing is to try and accelerate research towards clinical trials and new drug targets as fast as we can.
So, we are up in the top left. We are doing the genetics and we are trying to find these hits, which are the red circles, that will lead us to understanding what’s going wrong for people with ME and how the different genes and variants relate to one another in a disease network. That will help to, potentially, repurpose drugs if there are any. We’ll compare it to known drugs and databases and from that there will be an opportunity to test drugs in trials on cases and controls.
Now, of course, we’re only in the top left-hand corner of this graph at the moment, but we’re planning ahead. As many people know, we are already working with PrecisionLife, an artificial intelligence company, who have partners in Pharma, so that will then provide an acceleration of anything that we produce from DecodeME into the right fields towards new drugs and new drug targets.
ANDY
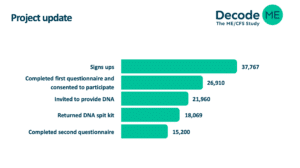
Slide 7, 14:59
Thank you Chris and Sonya.
I’m here to finish up our slides. As you can see, we’ve got a project update on the numbers of people who have taken part.
We started with almost 38,000 people who signed up to the study, who created an account with us. Just under 27,000 of you completed the first questionnaire and just that part alone provided a lot of valuable data which will be of use moving forward.
From those, just under 22,000 were invited to provide DNA. Just over 18,000 of you have returned those DNA kits and just over 15,000 completed the second questionnaire.
All of that is a fantastic result. As a patient myself, I can be tempted to look at those figures, particularly the top line and think we started with a large number, but then we’re losing them, losing numbers as we go down.
That is something that happens in studies. For various reasons people do not take part in the next stage, which obviously is their choice, and even to get to the second questionnaire, where over half of you were willing to take part in that, just shows what a fabulous contribution you’ve all made to DecodeME, thank you. Thank you all for your efforts. I know personally, the cost in energy and time that takes.

Slide 8, 17:06
In terms of next steps, well we’ve already kind of covered it. We are going to continue to send those batches of DNA to ThermoFisher for genotyping, get that genetic data back, and do all the necessary analysis, which is more easily said than done. It takes far more time to actually do that analysis than, obviously, to say that sentence!
We will publish the results eventually. That will come, well, ultimately, when it’s ready. There is great awareness throughout the team that we would like to do this as quickly as possible, but that is balanced against the quality of our final output and ultimately within the time limits that we have. We are aiming for high quality of that final output, because that will provide a starting point and a continuation for further research in the future.
As you can see on the next slide, we are going to be opening up our access process for the data. This process will allow other researchers to apply to us for access to that data to inform and form the basis for future research from them. We’re also going to continue working on plans to build longevity, as much as we can, for the DecodeME cohort. Basically, looking forward again to provide value to the community for not only for the money given to us by the funders, but again, the energy and time that you have invested in us.
SONYA
Thank you Chris and thank you Andy.
We’ve had lots of questions coming in. The first question that I wanted to pick up is related to what you were saying, Chris, about some of the delays. And I think it would be really helpful if you could just talk a little bit more about the DNA samples.
People are concerned that they might have been lost due to the issues at UK Biocentre and are worried that if there have been issues with those, that people are going to be asked to provide another DNA sample.
So, could you possibly just say a bit more about the situation?
CHRIS
Thank you Sonya.
So, where samples were lost, and there were a couple of hundred that were lost, we’ve gone back and asked people for a second sample. We were already asking some people for second samples because sometimes the sample that’s provided doesn’t process, for a whole variety of reasons, and when that happened and there wasn’t enough DNA, for example, then we asked people for a second sample.
So, all of that was happening behind the scenes. I don’t have the numbers in front of me, but that was happening all the way through and we made sure that people could be given the opportunity of giving a second sample, because our value is that every single sample is incredibly important. We took that as a value right from the beginning and then we followed it all the way through.
There were cases downstream of that, the sample is not able to be taken forward, all the way down the process to the analysis. For example, where the DNA letter changes are read out, some of those are not taken forward. Those are minor. 99.8% of people, 99% of people, I don’t know what the number is. You can be reassured that your sample has been treated incredibly well, from receipt to data analysis, and that we’ve done all that we can to ensure that the value that it has is translated into scientific value.
SONYA
Thank you, Chris.
We’ve got quite a few questions around the questionnaires. They are now closed. Both the first and second questionnaires have closed. So, I’m really sorry if you’re part way through, or you missed the opportunity…
We are really grateful to you all, our numbers are brilliant. We are really pleased with responses that we’ve had, and we don’t want anyone to worry if they’ve missed out on that. We are delighted with the numbers that we’ve got.
We’ve had a question actually about the numbers which I’m going to give to you, Andy, which asks what numbers were we aiming for this study?
ANDY
As many as possible!
One of the many challenges for DecodeME as a study, is that it was one of the first times anything on this scale had ever been done. So, there were so many aspects of it where we had to take a best guess as to what was possible to be achieved and, to a large extent, they were achieved, or they were smashed by the community.
I was mentioning earlier about how it could be perceived that there is a drop off between the numbers who originally signed up, and then who answered the first questionnaire, and the numbers were getting smaller at every stage. That happens with basically every research study out there, but the numbers that continued to take part, who took that next step that we asked them to, gave them the opportunity to rank right up there with the best results from other studies from other fields.
So, the numbers that we were aiming for were our best guess about what was possible with the community and was also required for the scientific basis of the study. There always could be more, but we are absolutely delighted with the numbers that we did eventually get.
SONYA
Thank you, Andy.
Just a reminder that we’re now closed to both the DNA samples and questionnaires, so please, please don’t worry if you haven’t done them. We’ve had quite a few comments around that.
Also, a question around whether or not this study is going to be available to people in the US. This is a UK-only study and we’ve now closed recruitment, but as Chris shared, we are trying really hard to work with researchers in other countries, so that we can extend this study and hopefully replicate and validate any findings.
We’ve had some questions around transcripts and slides. Everything will be available afterwards. Do give us a little bit of time to get the film ready and the transcript sorted, but we will make sure those are up on the website and available for you afterwards.
There’s a question here, Chris, about the lost samples. Were they destroyed?
CHRIS
Where there was a barcode, and the fidelity of the barcode tracing was lost, we’ve destroyed those samples, because we would not know from whom they came. But as I said previously, we have gone back to those, whose samples were affected, and we’ve asked for second samples where possible.
SONYA
Thank you, Chris.
We’ve got quite a number of questions about drug testing. Will low-dose naltrexone and others be used? We don’t know. Our focus is on getting the genetic data and as Chris shared, we’re working with others to ensure that our data can be used by other researchers too. Chris, I don’t know if you want to add anything to that?
CHRIS
I just want to thank people for putting down in the second questionnaire all of the treatments that you’ve tried and saying whether you felt that they were helpful or not. That’s going to be incredible data to pour through and we going to do that as soon as we can.
SONYA
Thank you.
We got a few questions around data security. So, can you say a little bit more about how the samples were anonymised and genetic data secured, and who the data is going to be shared with, and what data will be shared.
CHRIS
Everything is in the participant information sheet that everyone will have seen at the beginning of their journey. Essentially, we have asked people whether or not you wish to consent for sharing your data, your DNA, whatever. We’ve also said quite openly if you don’t want to do that, that’s absolutely fine too.
For those people who have consented, we take everything that you’ve given us very seriously, as to data security, so we have gone round the houses with respect to ensuring that your data is held securely here. We don’t share personally identifiable information, except with the company that’s sent you the spit kit, if you got one, and when we shared that we did so under a contract. Everything was held securely and all personally identifiable information would be removed from their systems afterwards. So, this is a very high standard that we’ve adhered to, that every project like ours adheres to, and University of Edinburgh, as a data processor, treats very seriously. We have gone the through internal processes to ensure that we are held to those high standards that all of you deserve.
SONYA
Thank you.
We’ve got a question here, again, I think this is going to be for you, Chris, I understand you’ve previously discussed this research in terms of medication. I wanted to know does DNA affect our nervous system, and has anyone requested access to research in reference to the nervous system and current theories around nervous system dysregulation?
CHRIS
Well, the great thing about the genetic study that we’re doing is that it will answer the question, ‘What is going wrong? Whether it’s the nervous system, the immune system, whatever system.
If it is the nervous system, then indeed we know from other disorders that the nervous system can be changed by DNA letter changes and so that’s the reason, like most studies like this, we are doing a genetic study. We will be able to find out, if it is a nervous system issue, what cells are going wrong in the nervous system disease. If it’s in immune system cells, it’s exactly the same – what cells are going wrong?
What are they the cells only that have been changed because of an infection like a virus, and that will allow, not just us, but people worldwide to drill down with their own expertise, on the minutiae of what’s going wrong, with respect to molecules in cells. So, this is the launchpad for new research into the future, whether it’s nervous system or not.
SONYA
Thank you, Chris.
Still more questions around the questionnaires. We’re not giving results of the second questionnaires individually, but we are hoping to publish and we will do that when we have the results, we’ve analysed them and we’re convinced of the robustness of them, and we check and check and check, we will publish those and we will make them available as soon as we can.
We had a question saying ‘Will the results be put to the GMC?’ I think that might be the General Medical Council. Once the results are available, we will share that.
We’ve had another comment saying these webinars are a bit wordy.
I’m sorry that they’re not as accessible for you, as maybe others. We want to get as much information in as possible and we do recognise that’s not ok for everyone. We try and ensure that our blogs always have a quick read section and then more information, so we do try really hard. I have to say, that’s the massive value of having people with lived experience working with us as part of the team, and we’ve tried very hard to make everything as accessible as possible, but we do recognise there will always be gaps. I can only say we’re very sorry that we’re not able to make this less wordy for you, but the transcript will be available, so you can take it in chunks.
We’ve got questions here, what if ME patients do not have any genetic variation that makes us prone to the illness and that it is the result of e.g. infection, plus failure to rest with that? Would that show up Chris?
CHRIS
Yes. So, everything that we’re prone to is really a spectrum and it’s your environment through infection etc. that will push you towards being at greater risk, and it will be DNA letters that will push you to less risk or more risk. It’s the combination of those that plays out as to whether someone will have an ME diagnosis or not. Rather than being ‘Do you have a gene that means you’ll get ME?’ It’s not as simple as that.
This is a complex disorder and we absolutely know that two-thirds of people have an infection prior to ME onset. That’s telling us something isn’t it? This is telling us that, that infection has meant that it’s the environment that contributes hugely to people’s risk of ME.
That is why we’re looking at DNA. It is the DNA that can tell us what is going wrong. Not that the DNA is telling us that it’s the major component of what’s going on.
SONYA
Thank you, Chris.
I am very conscious that we haven’t got much time left and there are quite a lot questions. Just a reminder to people, we can’t answer questions about your individual circumstances, when you got ill, why you got ill, so I apologise if you’ve taken energy to send us a question. I hope you understand that that’s not something we’re focused on in this particular study or webinar.
Andy, do you expect or anticipate the study will result in the reclassification of CFS/ME, from the current classification as a neurological disorder, to something else?
ANDY
I think it all comes down to what our results demonstrate.
I have to admit that I’m not up on the exact processes as to how something is determined to be a neurological disease, and how it’s then defined as something different, so I can’t really give a greatly informed answer. So, my answer is unfortunately going back to, it will depend on results, which isn’t that helpful. But I think that’s where it is. That will be how we determine that, once we know what we found out.
SONYA
Thank you, Andy.
We’ve got lots of questions around how we might stratify the DNA, look at it from different perspectives, look at gender, look at age, those kinds of things. We’re absolutely going to be doing that.
Lots of lovely comments from people. Thank you, for feeding those back, we really do value your feedback, good and bad.
Question here: ‘Is it possible ME/CFS in an umbrella term for a number of different illnesses sharing the same symptoms and could it be that Long Covid, Fibromyalgia etc. are actually ME?’ And we’ve had a linked question around FND as well.
So, Chris, can I maybe ask you to take that, in the first instance?
CHRIS
Thank you and I apologise for being too wordy earlier.
About half of people with Long Covid have symptoms that match the symptoms of ME, so there is an overlap, but it’s not the same. And that means that we should know there are commonalities, but there are also differences and that’s exactly how we will treat it scientifically.
SONYA
Thank you.
We’ve got questions here around the blood brain barrier. Can I ask whether this research will show any anomalies within the hippocampus or other parts of the brain that controls the immune function response? Chris?
CHRIS
If there is a gene that does that, that controls the immune system from the hippocampus, then that hypothesis will be supported. There will be a 1,000 or more similar hypotheses that could yet be supported.
SONYA
What about international replication, is the methodology being replicated in Finland and the USA to ensure standardisation?
CHRIS
It will not be the same because for the people, their DNA is associated with their electronic health records, not a diagnosis of ME. But electronic health records should give us a good indication of whether what we are seeing, with precise ME, is also occurring for people with more general post-viral fatigue, which is how the electronic health records record anyone with ME, but others too.
Sorry, that’s complicated.
SONYA
And some of these questions are complicated and I think they’re brilliant. The engagement that we’ve had from people in the community is really good and I have to say, when we’ve had some dark moments, when things are going wrong, and we’ve faced huge hurdles, your support and your engagement has made a massive difference to us.
So, I’m afraid we’re coming to the end of the webinar now. I just want to say thank you to Chris and to Andy, but also all of the people working in the background.
As I said at the beginning, they’ve worked incredibly hard and are very dedicated too. The three of us tend to be the face of the study, but actually, there are many more faces in the background.
We’ve had a question about how many people that participated in the study represent the UK population. We work on the basis of 250,000 people in the UK with ME. We all know it’s a very old figure and outdated. Using this, around a tenth of that community have participated in this study. I think that is phenomenal and we should really celebrate that.
So, just to say that we will look at the remaining questions. We’ve got through a lot, but, if there are any questions, we think we can answer and put up onto the FAQ, on the website: www.decodeme.co.uk, then we will do.
There will be more webinars, there will be more blogs, and you can access the film of this and the transcript, hopefully in the next week or two on our website.
Thank you for your time and your energy.